[번역] Effective Go: Concurrency
2015-09-25
2016.10.04 - Effective Go의 한글화 작업이완료되었습니다. 아래 동시성 번역 역시 번역팀의 도움으로 갱신되었습니다.
Effective Go 의 한글화 문서를 보던 중, Concurrency에 대한 부분이 빠져 있어서 해당 부분만 따로 번역했습니다. 원문의 출처는 여기입니다.
통신에 의한 공유 (Share by communicating)
동시성 프로그래밍은 광범위한 주제이므로 여기에서는 Go에 한정된 중요한 것들에 대해서만 지면을 할애한다.
다양한 환경에서 동시성 프로그래은 공유 변수에 대한 정확한 접근을 구현하기 위해 엄수해야 하는 세세한 내용들로 어려워졌다. Go는 공유 변수가 채널을 돌려가며 전달된다는 점에서 다른 접근을 권장한다. 그리고 사실 공유 변수는 개별 쓰레드 실행에 의해서 결코 공유되지 않는다. 언제든지 하나의 고루틴이 값에 접근한다. 데이터 경쟁은 구현 설계상 발생할 수 없다. 이러한 사고방식을 권장하기 위해 이를 한 슬로건으로 줄였다:
공유 메모리로 통신하지 말라. 대신, 통신으로 메모리를 공유하라.
이런 접근은 너무 지나친 것일 수 있다. 예를 들어, 정수형 변수 주위에 뮤텍스를 두는 방식의 레퍼런스 카운트가 최고일지도 모른다. 그러나 상위 레벨에서 접근하는 방법으로써, 접근을 제어하는 채널을 사용하면 분명하고 정확한 프로그램을 보다 쉽게 작성할 수 있다.
이 모델에 대해 생각해보는 한가지 방법은 단일 CPU에서 실행되는 전형적인 단일 쓰레드 프로그램을 떠올려 보는 것이다. 여기에는 동기화를 위한 기본 자료형이 필요 없다. 지금 또다른 그 인스턴스를 실행시켜 보라. 그러나 역시 동기화가 필요하지 않다. 이제 그 두 개를 통신하게 하는데, 그 통신 자체가 동기화 장치(synchronizer)인 경우, 여전히 다른 동기화가 필요 없다. 예를 들어, 유닉스 파이프 라인은 이 모델에 완벽하게 들어 맞는다. 동시성에 대한 Go의 접근 방식이 호어(Hoare)의 통신 순차적 프로세스 (CSP, Communicating Sequential Processes)에서 비롯되었지만, 타입 안전이 보장되는 식의 일반화된 유닉스 파이프라고 볼 수 있다.
고루틴 (Goroutines)
쓰레드, 코루틴, 프로세스 등 기존의 용어는 부정확한 함의를 전달하기 때문에 고루틴이라고 부른다. 고루틴은 단순한 모델이다. 즉, 같은 주소 공간에서 다른 고루틴과 동시에 실행되는 함수이다. 고루틴은 가볍다. 스택 영역을 할당하는 것에 비해 비용이 적게 든다. 그리고 그 스택은 작은 크기로 시작된다. 그래서 저렴하다. 그리고 필요한만큼 힙 스토리지를 할당(또는 해제)하여 커진다.
고루틴은 OS의 다중 쓰레드에 멀티플렉싱되는데, I/O 작업을 위해 대기중일 때와 같이 하나의 고루틴이 블락이 되면 다른 고루틴이 계속 실행된다. 이런 설계는 쓰레드의 복잡한 생성과 관리에 대해 굳이 알 필요가 없게 해준다.
새 고루틴을 호출하여 실행하려면 go 키워드를 함수 또는 메쏘드 호출 앞에 둔다. 호출이 완료되면, 고루틴은 자동으로 종료된다. (백그라운드에서 명령을 실행하는 유닉스쉘 및 표기법과 유사한 효과이다.)
go list.Sort() // list.Sort를 (정렬이 완료될 때까지) 기다리지 말고 동시에 실행
함수 리터럴은 고루틴 호출에 유용할 수 있다.
func Announce(message string, delay time.Duration) {
go func() {
time.Sleep(delay)
fmt.Println(message)
}() //괄호 주목 - 반드시 함수를 호출해야 함
}
Go에서 함수 리터럴은 클로저이다. 즉, 함수가 참조하는 변수를 사용하는 동안에는 그 생존을 보장하는 방식으로 구현되어 있다는 것이다.
위의 예제는 함수가 종료를 알릴 방법이 없기 때문에 아주 실용적이진 않다. 이를 위해 채널이 필요하다.
채널 (Channels)
맵과 마찬가지로, 채널은 make로 할당되고, 그 결과 값은 실제 데이터 구조에 대한 참조로서 동작한다. 선택적인 정수형 매개변수가 주어지면, 채널에 대한 버퍼 크기가 설정된다. 이 값은 언버퍼드(Unbuffered) 또는 동기 채널에 대해서 기본값이 0이다.
ci := make(chan int) // 정수형의 언버퍼드 채널
cj := make(chan int, 0) // 정수형의 언버퍼드 채널
cs := make(chan *os.File, 100) // File 포인터형의 버퍼드 채널
언버퍼드 채널은 동기화로 값을 교환하며 두 계산(고루틴들)이 어떤 상태에 있는지 알 수 있다는 것을 보장하는 통신을 결합한다.
채널을 사용하는 멋있는 Go스러운 코드가 많다. 다음 한 예제로 시작해보자. 이전 섹션에서 백그라운드에서 정렬을 했다. 채널은 정렬이 완료될 때까지 고루틴 실행을 대기시킬 수 있다.
c := make(chan int) // 채널을 할당
// 고루틴에서 정렬 시작하고 완료되면 채널에 신호를 보냄
go func() {
list.Sort()
c <- 1 // 신호를 보내지만 값은 문제가 안됨
}()
doSomethingForAWhile()
<-c // 정렬이 끝날 때까지 기다리고 전달된 값은 버림
수신부는 수신할 데이터가 있을 때까지 항상 블락된다. 언버퍼드 채널이면, 송신부는 수신부가 값을 받을 때까지 블락된다. 버퍼드 채널이면, 값이 버퍼에 복사될 때까지만 송신부가 블락된다. 그러므로 버퍼가 꽉 차면, 이는 특정 수신부가 값을 획득할 때까지 대기 중이라는 것을 의미한다.
버퍼드 채널은 세마포처럼 사용될 수 있다. 예를 들어 처리량을 제한하는 것이다. 다음 예제에서, 들어오는 요청은 값을 채널에 전송하는 handle에 넘겨진다. 요청을 처리한 후, 다음 (요청) 소비자에 대해 세마포를 준비하는 채널에서 값을 수신한다.
var sem = make(chan int, MaxOutstanding)
func handle(r *Request) {
sem <- 1 // 액티브큐가 비워질 때까지 대기
process(r) // 오래 걸릴 수 있는 작업
<-sem // 완료, 실행될 다음 요청을 활성화
}
func Serve(queue chan *Request) {
for {
req := <-queue
go handle(req) // 끝날 때까지 대기하지 않음
}
}
일단 MaxOutstanding 핸들러가 process를 실행하게 되면, 기존 핸들러 중 하나가 완료되고 버퍼로부터 값을 받을 때까지 더 이상의 꽉 찬 채널 버퍼에 전송하는 것은 블락될 것이다.
그렇지만 이 설계는 문제가 있다. 즉, 전체 요청에서 겨우 MaxOutstanding 수만큼 process를 실행할 수 있음에도 서버는 들어오는 모든 요청에 대해 새로운 고루틴을 생성한다는 것이다. 그 결과, 요청이 너무 빨리 들어올 경우, 무제한으로 리소스를 낭비할 수 있다. 이 결함은 Serve를 고루틴을 생성하는 게이트로 수정해서 처리할 수 있다. 확실한 솔루션은 다음과 같지만, 나중에 수정하게 될 버그가 있다는 것에 주의하라.
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func() {
process(req) // 버그, 아래 설명을 참고
<-sem
}()
}
}
버그는 Go for 루프에 있다. 루프 변수는 각 반복마다 재사용되어 동일한 req 변수가 모든 고루틴에 걸쳐 공유된다. 이는 원하는 바가 아니다. 각 고루틴마다 구별된 req 변수를 가지도록 해야한다. 다음은 이를 위한 한 가지 방법으로, 고루틴의 클로져에 대한 인자로 req의 값을 전달하는 것이다:
func Serve(queue chan *Request) {
for req := range queue {
sem <- 1
go func(req *Request) {
process(req)
<-sem
}(req)
}
}
이전 버전과 클로져가 어떻게 선언되고 실행되는지 차이점을 보기 위해 다음 버전을 비교해보라. 또다른 솔루션은 다음 예제처럼 그냥 같은 이름의 새로운 변수를 생성하는 것이다.
func Serve(queue chan *Request) {
for req := range queue {
req := req // 고루틴을 위한 새로운 req 인스턴스를 생성
sem <- 1
go func() {
process(req)
<-sem
}()
}
}
이상한 코드를 작성하는 것처럼 보일 수 있다.
req := req
하지만 Go에서 이렇게 하는 것은 합법적이고 Go 언어다운 코드이다. 이름이 같은 새로운 버전의 변수가 의도적으로 루프 변수를 지역적으로 가리지만, 각 고루틴에 대해서는 유니크한 값이다.
서버를 작성하는 일반적인 문제로 돌아가면, 리소스를 잘 관리하는 다른 방법은 요청 채널을 읽는 모든 handle 고루틴을 고정된 수에서 시작하는 것이다. 고루틴의 수는 process가 동시에 호출되는 수를 제한한다. Serve 함수는 종료 신호를 수신하게 되는 채널도 (인자로) 받고 있으므로 고루틴이 시작되면, 이 채널로부터의 수신은 블락된다.
func handle(queue chan *Request) {
for r := range queue {
process(r)
}
}
func Serve(clientRequests chan *Request, quit chan bool) {
// 핸들러 시작
for i := 0; i < MaxOutstanding; i++ {
go handle(clientRequests)
}
<-quit // 종료 신호를 받을 때까지 대기
}
채널의 채널 (Channels of channels)
Go의 가장 중요한 속성 중 하나는 채널이 다른 것과 마찬가지로 할당되고 전달될 수 있는 일급변수(first-class value)라는 것이다. 이 속성의 일반적인 사용은 안전한 병렬 역다중화(parallel demultiplexing)를 구현하는 것이다.
이전 섹션의 예제에서, handle 은 요청에 대해서는 이상적인 핸들러였으나 핸들러가 다루는 타입은 정의하지 않았다. 해당 타입이 회신을 하는 채널을 포함하는 경우, 각 클라이언트는 자신에게 응답 경로를 제공할 수 있다. 다음은 Request 타입의 개략적인 정의이다.
type Request struct {
args []int
f func([]int) int
resultChan chan int
}
클라이언트는 함수와 그 인자뿐만 아니라 요청 객체 안에서 응답을 수신하는 채널을 제공하고 있다.
func sum(a []int) (s int) {
for _, v := range a {
s += v
}
return
}
request := &Request{[]int{3, 4, 5}, sum, make(chan int)}
// 요청 전송
clientRequests <- request
// 응답 대기
fmt.Printf("answer: %d\n", <-request.resultChan)
서버 측에서는 핸들러 함수만 수정한다.
func handle(queue chan *Request) {
for req := range queue {
req.resultChan <- req.f(req.args)
}
}
실제로 사용하기 위해서는 아직 할 일이 많은 것이 명백하지만, 이 코드는 속도 제한, 병렬, 넌블락 RPC 시스템을 위한 프레임워크이다. 그리고 뮤텍스는 눈에 보이지 않는다.
병렬화 (Parallelization)
이러한 아이디어의 또 다른 응용 프로그램은 멀티코어 CPU에 대해 계산을 병렬처리하는 것이다. 계산을 독립적으로 실행할 수 있는 부분들로 분리할 수 있다면, 각 부분들이 완료될 때 신호를 보내는 채널들로 병렬처리할 수 있다.
벡터 아이템에 대한 실행 비용이 비싼 연산이 있다고 가정해보자. 그리고 다음 이상적인 예제에서와 같이 각 아이템을 연산한 값은 독립적이다.
type Vector []float64
// v[i], v[i+1]에서 v[n-1]까지 연산을 적용
func (v Vector) DoSome(i, n int, u Vector, c chan int) {
for ; i < n; i++ {
v[i] += u.Op(v[i])
}
c <- 1 // 이 부분이 완료되면 신호함
}
루프에서 독립적으로 각 부분들을 CPU당 하나씩 실행시킨다. 이들은 어떤 순서로도 완료될 수 있지만 순서는 문제되지 않는다. 그러므로 모든 고루틴를 실행시킨 후 채널을 비워서 그냥 완료 신호를 카운트한다.
const numCPU = 4 // CPU 코어수
func (v Vector) DoAll(u Vector) {
c := make(chan int, numCPU) // 버퍼는 선택적이나 상식적
for i := 0; i < numCPU; i++ {
go v.DoSome(i*len(v)/numCPU, (i+1)*len(v)/numCPU, u, c)
}
// 채널을 비움
for i := 0; i < numCPU; i++ {
<-c // 한 태스크가 끝날 때까지 대기
}
// 모두 완료
}
numCPU을 상수값으로 생성하기보다는 적절한 값을 런타임시에 요구할 수 있다. runtime.NumCPU 함수는 장비의 CPU 하드웨어 코어수를 반환한다. 그래서 아래와 같이 작성할 수 있다.
var numCPU = runtime.NumCPU()
또한 Go 프로그램은 동시에 실행할 수 있는 사용자 지정 코어수를 보고하는 (또는 설정하는) runtime.GOMAXPROCS 함수가 있다. runtime.NumCPU의 값이 기본값이지만, 비슷하게 명명된 환경 변수 설정에 의해 혹은 양수의 인자로 함수를 호출하여 재정의할 수 있다. 0으로 호출하면 바로 값을 조회한다. 따라서 사용자의 리소스 요청을 따르고 싶은 경우, 다음과 같이 작성해야 한다.
var numCPU = runtime.GOMAXPROCS(0)
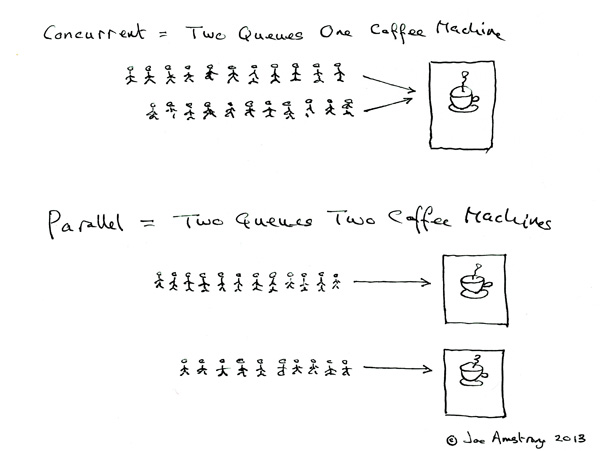
컴포넌트를 독립적으로 처리하여 프로그램을 구조화하는 동시성과 다중 CPU에서 효율성을 위해 계산을 병렬로 처리하는 병렬성의 개념을 혼동하지 않길 바란다. Go의 동시성 특징이 병렬 계산으로 문제를 쉽게 구조화할 수 있지만, Go는 병렬이 아닌 동시성 언어이고, 모든 병렬화 문제가 Go에 들어맞지는 않는다. 이 구분에 대한 논의는 이 블로그 포스트에 인용된 토크를 참조하라.
역자 주: 동시성 프로그래밍과 병렬 프로그래밍의 차이는 아래 그림을 참조 (출처)
누설 버퍼 (A leaky buffer)
비동시성(non-concurrent) 개념도 동시성 프로그래밍 도구로 쉽게 표현할 수 있다. 다음은 RPC 패키지에서 추출한 예제이다. 클라이언트 고루틴은 아마도 네트워크인 특정 소스의 데이터를 반복해서 수신한다. 버퍼의 할당과 해제를 피하기 위해서 free list를 유지하며 이를 대신할 버퍼 채널을 사용한다. 채널이 비어 있으면 새로운 버퍼가 할당된다. 일단 메시지 버퍼가 준비되면 serverChan의 서버로 송신한다.
var freeList = make(chan *Buffer, 100)
var serverChan = make(chan *Buffer)
func client() {
for {
var b *Buffer
// 사용할 수 있는 버퍼를 획득하거나 그렇지 않다면 할당
select {
case b = <-freeList:
// 하나를 획득하고 아무 작업도 하지 않음
default:
// 획득할 버퍼가 없으니 새 버퍼를 할당함
b = new(Buffer)
}
load(b) // 네트워크에서 다음 메세지를 읽음
serverChan <- b // 서버에 전송
}
}
서버 루프는 각 클라이언트로부터 메시지를 수신해서 처리하고, free list에 버퍼를 반환한다.
func server() {
for {
b := <-serverChan // 동작을 위해 대기
process(b)
// 가능할 경우 버퍼를 재사용
select {
case freeList <- b:
// free list의 버퍼. 아무 것도 하지 않음
default:
// free list가 꽉 참, 그냥 계속
}
}
}
클라이언트는 freeList에서 버퍼를 획득하려고 시도하는데, 버퍼를 사용할 수 없는 경우에는 새로운 버퍼를 할당한다. 리스트가 꽉 차 있지 않는 이상, 서버는 버퍼를 freeList에 송신하여 프리 리스트에 버퍼 b를 다시 둔다. 리스트가 꽉 차 있는 경우, 버퍼는 바닥에 떨어져 가비지 콜렉터에 의해 회수된다. (select 구문에서 default 절은 다른 case가 준비되지 않은 경우에 실행된다. 이는 select는 결코 블락되지 않는다는 것을 뜻한다.) 단지 몇 줄로 버퍼 채널과 버퍼 크기를 부기하는 가비지 컬렉터에 기대어 구현된 누설 버킷 프리 리스트(leaky bucket free list)를 만들었다.
이상, 나머지는 여기 한글화 문서를 참조하길 바란다.